
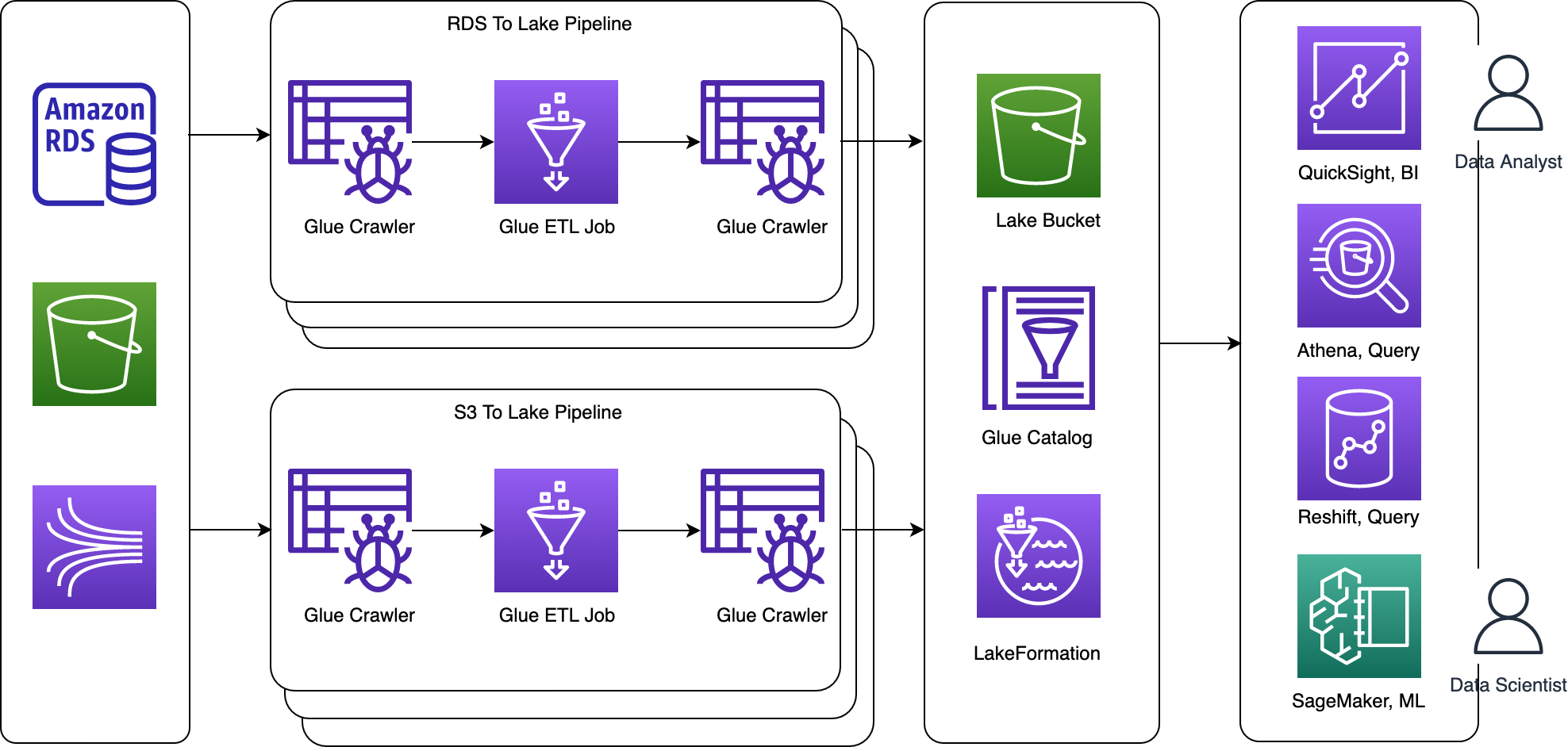
Introduction#
Github shows a simple data lake using serverless data processing tools like Glue, Athena, Redshift, SageMaker, etc. I does learn from this aws sample repository, while this is written in a software manner (wanted to be reusable and extensiable), but it is not easy to understand. So I would like to
- Create a simple, easy to understand version
- Others can quickly learn, then build by themselve, not blindly clone a sample and run it
- For learning purpose
There are some key points
- Lake Formation underlying access control, register data, grant lake permision, grant data location
- Glue crawler and and Glue data catalog
- Glue ETL job with Spark under the hood (Glue Dyanmic Data Frame)
- Query with Athena and visualize with QuickSight
- Redshift and SageMaker shown in another blogs
LakeFormation Access Control#
It is essential to understand how lakeformation control access to data analysts and ETL (glue role).
- register admin such as cdk role
- register s3 data (lake)
- grant permission to data analysts
- grant permission to glue role
To control which catalog table, column a data analyst can query, lakeformation grants data lake permssions to the DA, or role. Lakeformation will provide the DA temporary credentials to access data in S3 and corressponding tables so they can query data without directly setting IAM for the DA. At this moment, however, still need to setup the DA has write permission to athena query result location.
To control a ETL pipeline can create catalog tables, lakeformation grants data location permissions to a glue role (ETL role). When a S3 bucket has been registered to the lakeformation, without the data location permission, no catalog tables can be created. However, still need to setup IAM so the ETL can read the source (S3, RDS connection, etc), and permission to write to destination in S3.
To enable CDK role run the grant permissions, the CDK role should be registered as an admin role to lakeformation.
Register Admin and Data#
This is first and important step. By registering cdk execution role as an Admin in Lake Formation, then cdk can deploy things, otherwise, it will fail.
new aws_lakeformation.CfnDataLakeSettings(this, 'LakeFormationAdminSetting', {admins: [{dataLakePrincipalIdentifier: Fn.sub((this.synthesizer as DefaultStackSynthesizer).cloudFormationExecutionRoleArn)}]})
Then start to register data (bucket prefixes) together with a role so Lake Formation will manage access on be-half of you. This is called underlying access control
- an IAM user for a data analyst will get temporary credentials from Lake Formation to query data in S3
- an Glue role will get temporary credentials from Lake Formation to create catalogs
new aws_lakeformation.CfnResource(this, 'RegisterDataLakeFormation', {resourceArn: props.registerBucketData,// role which lake formation access s3// roleArn: "",// use AWSServiceRoleForLakeFormationDataAccess roleuseServiceLinkedRole: true})
Create Data Analyst User#
- create an IAM user for a data analyst
- attach AmazonAthenaFullAccess role the DA
- attach an inline policy allow writing query result to s3
const secret = new aws_secretsmanager.Secret(this, `${props.userName}Secret`, {secretName: `${props.userName}Secret`,generateSecretString: {secretStringTemplate: JSON.stringify({ username: props.userName }),generateStringKey: "password",},});// create an iam user for data analyst (da)const daUser = new aws_iam.User(this, `${props.userName}IAMUser`, {userName: props.userName,// password: SecretValue.unsafePlainText("Demo#2023"),// password: SecretValue.secretsManager(secret.secretName),password: secret.secretValueFromJson("password"),passwordResetRequired: false,});
attach policy to access athena and quicksight
daUser.addManagedPolicy(aws_iam.ManagedPolicy.fromAwsManagedPolicyName("AmazonAthenaFullAccess"));// access athena result query in s3daUser.addToPolicy(new aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ["s3:*"],resources: [props.athenaResultBucketArn],}));daUser.addToPolicy(new aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ["quicksight:*"],resources: ["*"],}));
Grant Database Permissions#
- grant an iam user (DA) to access database, table
- lakeformation privde temporary access for the DA to query data in S3
new aws_lakeformation.CfnPrincipalPermissions(this,`${userArn}-UserReadCatalog`,{permissions: databasePermissions,permissionsWithGrantOption: databasePermissions,principal: {dataLakePrincipalIdentifier: userArn},resource: {database: {catalogId: this.account,name: databaseName}}})
Grant Data Location#
- grant glue role to write, create resource (databses catalog)
new aws_lakeformation.CfnPrincipalPermissions(this, `GlueWriteCatalog-1`, {permissions: ['DATA_LOCATION_ACCESS'],permissionsWithGrantOption: ['DATA_LOCATION_ACCESS'],principal: {dataLakePrincipalIdentifier: roleArn},resource: {dataLocation: {catalogId: this.account,resourceArn: `arn:aws:s3:::${locationBucket}${bucketPrefix}`}}})
ETL Pipeline S3 to Lake#
- Use Glue workflow to build a pipeline
- Use the interactive session notebook to depvelop pyspark code
- Please setup a role to use the session note book pass role required
- Grant location permission to the Glue ETL pipeline role to write data to lake via lake formation authorization
lake formation grant location permission to the ETL role
lakeFormation.grantGlueRole({pipelineName: 'Etl',roleArn: etl.glueRole.arn,bucketPrefix: 'spark-output',locationBucket: config.dataLocationBucket})
the inside function
public grantGlueRole({pipelineName,roleArn,bucketPrefix,locationBucket,}: {pipelineName: string;roleArn: string;bucketPrefix: string;locationBucket: string;}) {const permision = new aws_lakeformation.CfnPrincipalPermissions(this,`GlueWriteCatalog-${pipelineName}`,{permissions: ["DATA_LOCATION_ACCESS"],permissionsWithGrantOption: ["DATA_LOCATION_ACCESS"],principal: {dataLakePrincipalIdentifier: roleArn,},resource: {dataLocation: {catalogId: this.account,resourceArn: `arn:aws:s3:::${locationBucket}/${bucketPrefix}`,},},});permision.addDependency(this.lakeCdkAmin);}
Assess to store the pyspark code
const pythonScriptPath = new Asset(this, 'etl-spark-script', {path: path.join(__dirname, './../script/spark_transform.py')})
role for the Glue ETL pipeline
// glue roleconst role = new aws_iam.Role(this, 'GlueRoleForEtlWorkFlow', {roleName: 'GlueRoleForEtlWorkFlow',assumedBy: new aws_iam.ServicePrincipal('glue.amazonaws.com')})role.addManagedPolicy(aws_iam.ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSGlueServiceRole'))role.addManagedPolicy(aws_iam.ManagedPolicy.fromAwsManagedPolicyName('CloudWatchAgentServerPolicy'))// where it crawl datarole.addToPolicy(new aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ['s3:ListObject', 's3:GetObject'],resources: [`arn:aws:s3:::${props.soureBucket}`,`arn:aws:s3:::${props.soureBucket}/*`]}))role.addToPolicy(new aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ['lakeformation:GetDataAccess'],resources: ['*']}))pythonScriptPath.grantRead(role)
create a Glue workflow
const workflow = new aws_glue.CfnWorkflow(this, 'EtlWorkFlow', {name: 'EtlWorkFlow',description: 'demo'})var s3Targets: aws_glue.CfnCrawler.S3TargetProperty[] = []props.soureBucketPrefixes.map(prefix => {s3Targets.push({path: `s3://${props.soureBucket}/${prefix}`,sampleSize: 1})})
craw the source data with a Glue crawler
const crawler = new aws_glue.CfnCrawler(this, 'CrawRawData', {name: 'CrawRawData',role: role.roleArn,targets: {s3Targets: s3Targets},databaseName: 'default',description: 'craw a s3 prefix',tablePrefix: 'etl'})
spark job to transform the data
const job = new aws_glue.CfnJob(this, 'TransforJobWithSpark', {name: 'TransformJobWithSpark',command: {name: 'glueetl',pythonVersion: '3',scriptLocation: pythonScriptPath.s3ObjectUrl},defaultArguments: {'--name': ''},role: role.roleArn,executionProperty: {maxConcurrentRuns: 1},glueVersion: '3.0',maxRetries: 1,timeout: 300,maxCapacity: 1})
another crawler to write to catalog
const crawlerTransforedData = new aws_glue.CfnCrawler(this,'CrawTransformedData',{name: 'CrawTransformedData',role: role.roleArn,targets: {s3Targets: [{path: `s3://${props.soureBucket}/spark-output`,sampleSize: 1}]},databaseName: 'default',description: 'craw transformed data',tablePrefix: 'transformed'})
the starting trigger of the workflow
const trigger = new aws_glue.CfnTrigger(this, 'StartTriggerDemo', {name: 'StartTriggerDemo',description: 'start the etl job demo',actions: [{crawlerName: crawler.name,timeout: 300}],workflowName: workflow.name,type: 'ON_DEMAND'})
conditional trigger the pyspark ETL job
const triggerEtl = new aws_glue.CfnTrigger(this, 'TriggerTransformJob', {name: 'TriggerTransformJob',description: 'trigger etl transform',actions: [{jobName: job.name,timeout: 300}],workflowName: workflow.name,type: 'CONDITIONAL',//true: when working with conditional and schedulestartOnCreation: true,predicate: {conditions: [{logicalOperator: 'EQUALS',crawlState: 'SUCCEEDED',crawlerName: crawler.name}]// logical: "ANY",}})
conditional trigger the final crawler
const triggerTransformedCrawler = new aws_glue.CfnTrigger(this,'TriggerTransformedCrawler',{name: 'TriggerTransformedCrawler',actions: [{crawlerName: crawlerTransforedData.name,timeout: 300}],workflowName: workflow.name,type: 'CONDITIONAL',startOnCreation: true,predicate: {conditions: [{logicalOperator: 'EQUALS',state: 'SUCCEEDED',jobName: job.name}]}})
ETL Pipeline RDS to Lake#
configure glue role with permissions
- read data source in S3, RDS
- write to a destination in S3
- lakeformation grant location permission to ETL can create catalog tables
const role = new aws_iam.Role(this, `${props.name}-RoleForGlueEtljob`, {roleName: `${props.name}-RoleForGlueEtljob`,assumedBy: new aws_iam.ServicePrincipal('glue.amazonaws.com')})role.addManagedPolicy(aws_iam.ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSGlueServiceRole'))role.addManagedPolicy(aws_iam.ManagedPolicy.fromAwsManagedPolicyName('CloudWatchAgentServerPolicy'))role.addToPolicy(new aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ['s3:GetObject', 's3:PutObject'],resources: [`arn:aws:s3:::${props.destBucket}/*`]}))role.addToPolicy(new aws_iam.PolicyStatement({effect: Effect.ALLOW,actions: ['lakeformation:GetDataAccess'],resources: ['*']}))etlScript.grantRead(role)
ect script
const etlScript = new aws_s3_assets.Asset(this, 'EtlScriptRdsToLakeDemo', {path: path.join(__dirname, './../script/etl_rds_to_lake.py')})
JDBC connection
- please pay attention to the format of jdbc connection
- please ensure the rds security group has a self-referencing
jdbc:protocol://host:port/database
then create a connection as below
const connection = new aws_glue.CfnConnection(this, 'RdsConnectionDemo', {catalogId: this.account,connectionInput: {connectionType: 'JDBC',description: 'connect to rds',name: 'RdsConnectionDemo',connectionProperties: {JDBC_CONNECTION_URL: 'jdbc:mysql://host-database:port/database',USERNAME: 'xxx',PASSWORD: 'xxx'},physicalConnectionRequirements: {availabilityZone: 'xxx',securityGroupIdList: ['xxx'],subnetId: 'xxx'}}})
create a worflow trigger => crawlRDS => trigger => etlJob. First create a crawler to craw the RDS
const crawler = new aws_glue.CfnCrawler(this, 'CrawlRdsDemo', {name: 'CrawlRdsDemo',role: role.roleArn,targets: {jdbcTargets: [{connectionName: connection.ref,path: 'sakila/articles'}]},databaseName: 'default',tablePrefix: 'RdsCrawl'})
create an ETL job to transform the data and write to s3 lake
const job = new aws_glue.CfnJob(this, 'CrawRdsToLakeDemo', {name: 'CrawRdsToLakeDemo',command: {name: 'glueetl',pythonVersion: '3',scriptLocation: etlScript.s3ObjectUrl},defaultArguments: {'--name': ''},role: role.roleArn,executionProperty: {maxConcurrentRuns: 10},connections: {connections: [connection.ref]},glueVersion: '3.0',maxRetries: 0,timeout: 300,maxCapacity: 1})
create a workflow: trigger => craw rds => trigger => etl transform
const workflow = new aws_glue.CfnWorkflow(this, 'EtlRdsToLakeWorkFlow', {name: 'EtlRdsToLakeWorkFlow',description: 'rds to lake demo'})
the starting trigger to start the workflow
new aws_glue.CfnTrigger(this, 'TriggerStartCrawRds', {name: 'TriggerStartCrawRds',description: 'trigger start craw rds',actions: [{crawlerName: crawler.name,timeout: 420}],workflowName: workflow.name,type: 'ON_DEMAND'})
another trigger to start the etl job
new aws_glue.CfnTrigger(this, 'TriggerTransformRdsTable', {name: 'TriggerTransformRdsTable',description: 'trigger transform rds table',actions: [{jobName: job.name,timeout: 420}],workflowName: workflow.name,type: 'CONDITIONAL',startOnCreation: true,predicate: {conditions: [{logicalOperator: 'EQUALS',crawlState: 'SUCCEEDED',crawlerName: crawler.name}]}})
ETL PySpark#
Glue does not understand unsigned int from mysql
ApplyMapping_node2 = ApplyMapping.apply(frame=MySQLtable_node1,mappings=[("last_update", "timestamp", "last_update", "string"),("last_name", "string", "last_name", "string"),("actor_id", "int", "actor_id", "string"),("first_name", "string", "first_name", "string"),],transformation_ctx="ApplyMapping_node2",)
- option 1. use PySpark TypeStructure
from pyspark.sql.types import *customSchema = StructType([StructField("a", IntegerType(), True),StructField("b", LongType(), True),StructField("c", DoubleType(), True)])df = spark.read.schema(customSchema).parquet("test.parquet")
- option 2. after load data from database to lake, use crawler again
Load Data to Database#
- launch an ec2 instance and connect with the database
- double check the S3 endpoint RDS private subnet => S3
open port 3306 peer security group with database
install mariadb db client
sudo apt updatesudo apt install mariadb-server
download sample sakila data
wget https://downloads.mysql.com/docs/sakila-db.zip .
load sakila data into the database
cdk sakila-dbexport host=""export port=3306export user="demo"export password=""mysql --host=$host --user=$user --password=$passwordmysql --host=$host --user=$user --password=$password -f < sakila-schema.sqlmysql --host=$host --user=$user --password=$password -f < sakila-data.sql
Visualization with Quicksight#
- go to quciksight console and create a new account
- inside quicksight create a new dataset connecting to athena
- then create a visualization analysis from there
quicksight: minh-tran
Troubleshooting#
- Cdk execution role must be admin first, the delay, then deploy next stacks
- Clean lake permission principales before deploy (double check already existed one)
- Ensure that the role for deploying CDK stack is choosend as an admin in lakeformation
- Goto the LakeFormation console and select the CDK deploy role to be an admin
- Database and table has different set of permissions
{"Version": "2012-10-17","Statement": [{"Effect": "Allow","Action": ["lakeformation:GetDataAccess","glue:GetTable","glue:GetTables","glue:SearchTables","glue:GetDatabase","glue:GetDatabases","glue:GetPartitions","lakeformation:GetResourceLFTags","lakeformation:ListLFTags","lakeformation:GetLFTag","lakeformation:SearchTablesByLFTags","lakeformation:SearchDatabasesByLFTags","athena:*"],"Resource": "*"},{"Effect": "Allow","Action": ["s3:*"],"Resource": ["arn:aws:s3:::bucket-name", "arn:aws:s3:::bucket-name/*"]}]}
- RDS security group self-referencing
const securityGroupRds = new aws_ec2.SecurityGroup(this, 'SecurityGroupRds', {securityGroupName: 'SecurityGroupRds',vpc: vpc})securityGroupEc2.addIngressRule(securityGroupRds,aws_ec2.Port.allTcp(),'allow all its own')
- JDBC connection format
jdbc:protocol://host:port/database
Deploy#
There are serveral stacks to deploy. First, check cdk synth
cdk bootstrap aws://115736523957/us-east-1cdk --app 'npx ts-node --prefer-ts-exts bin/vpc-rds-ec2.ts' synthcdk --app 'npx ts-node --prefer-ts-exts bin/data-lake-demo.ts' synth
then deploy vpc, rds and an ec2 which write data to the rds
cdk --app 'npx ts-node --prefer-ts-exts bin/vpc-rds-ec2.ts' deploy --all
then deploy the lakeformation, s3 lake, and and s3 pipeline
cdk --app 'npx ts-node --prefer-ts-exts bin/data-lake-demo.ts' deploy --all
then deploy and rds pipeline
update the config.ts to provide rds connection information
update the bin/data-lake-demo.ts by uncomment rds pipeline
then deploy
cdk --app 'npx ts-node --prefer-ts-exts bin/data-lake-demo.ts' deploy --all
then deploy an data analyst
update bin/data-lake-demo.ts and uncomment a data analyst
then deploy a data analyst
cdk --app 'npx ts-node --prefer-ts-exts bin/data-lake-demo.ts' deploy --all